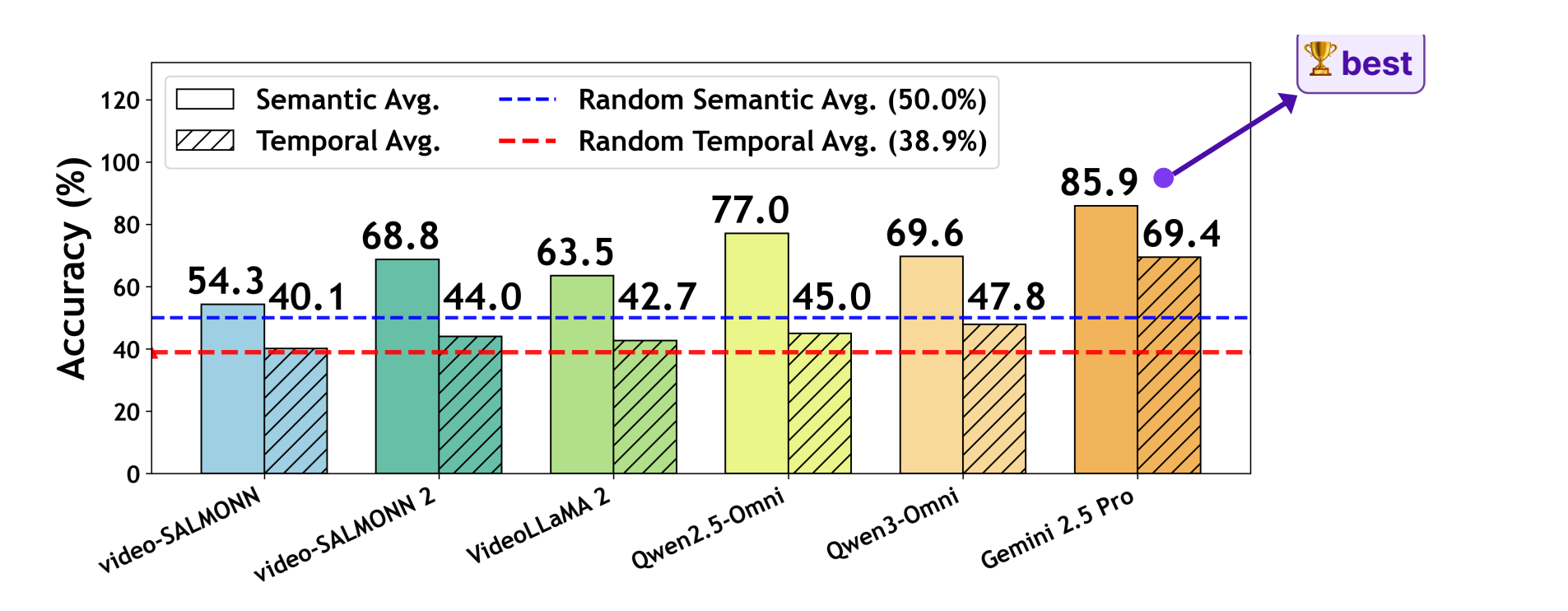
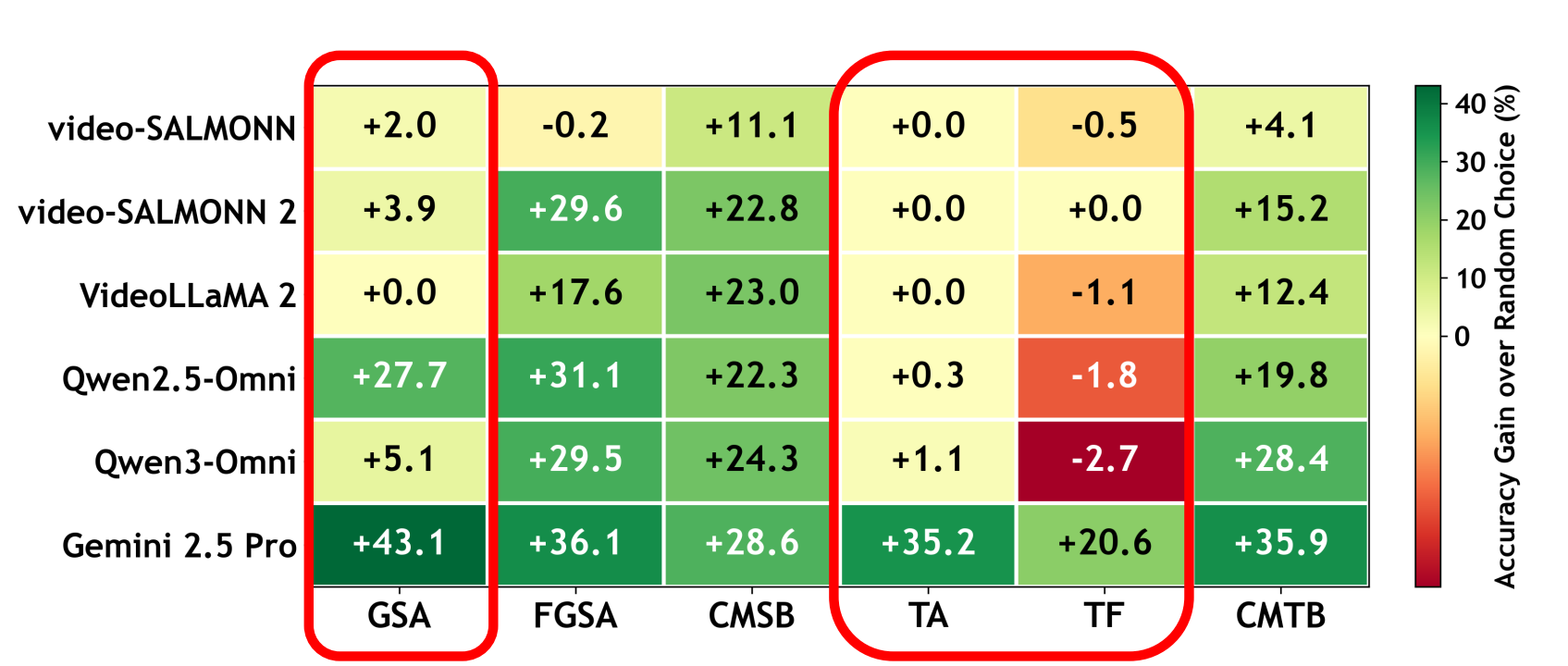
Motivation: Speech Content ≠ Visual Evidence
Existing audio-visual hallucination studies mainly test whether environmental sound events are visually present. SVHalluc studies a more challenging setting: speech can mention objects, actions, and temporal references that are not supported by the current video.

Unlike environmental sounds, speech carries rich semantic and temporal content. Models should not treat what is said as what is seen.
Sound event hallucination
Prior work often asks whether a heard environmental sound, such as a cat meowing, corresponds to a visible event.
Speech-induced hallucination
Speech can mention non-visible content. For example, a model may hear “egg” and hallucinate that an egg is visible.
Ground speech in vision
SVHalluc evaluates whether AV-LLMs can verify spoken content against visual evidence, rather than simply relying on the transcript.